
Understanding Backpropagation for ConvNets
Convolutional Neural Networks or ConvNets are everywhere these days thanks to its extensive application in a wide range of tasks starting from toy examples such as dogs vs cats classifications to much more intricate autonomous cars and likes. In fact, it is also pretty easy to learn the basics of these networks and understand how they outperform fully-connected networks in solving advanced problems. A series of great tutorials are available online which include masterpieces like Andrew Ng’s deeplearning.ai in Coursera, Jeremy Howard’s Fast.ai, Udacity’s Deep Learning nanodegree and of course the famous cs231n by Stanford. In case you are just starting out your journey in the deep learning space, I would highly recommend you check out the above courses.
What I found to be not so trivial however, perhaps even after you are off the ground with a few deep learning models in your pocket, is understanding how backpropagation works for these networks. That being said, I assume that you are fairly familiar with the backpropagation algorithm for shallow neural networks. Again, if you are not so comfortable with the weight updates through gradients in different layers, please check out the above courses. This article by Michael Nielsen goes pretty deep into the underlying math of neural networks in case you are interested.
This post, however, is not intended to derive the mathematical equations for the backpropagation for convolutional networks. Rather, it is aimed at providing you with a conceptual clarity about how it works. By the end of this article, you should be in a comfortable position to do the math by yourself with your favourite notational nuance. In the following section, we shall see how the forward and backward pass look like for a convolutional layer and how it differs from a fully-connected layer. Just one caveat before we dive in, this is my first try to write a blog post, so please bear with me in case something is not so well conveyed or overemphasised.
Instead of trying to master the backpropagation for a particular type of network — what I found more useful is to have a clear idea about what a backward pass would achieve given a forward pass. It really helps to think about the network as a computation graph where we feed in certain inputs which propagate forward through the layers to generate an output, then we use that output to calculate a cost function (you can think of it as a feedback from the labels for the current pass) and then calculate the gradients for that cost function which in turn propagate back through the network adjusting the weights (and biases) up till the first hidden layer. As such, we can calculate the activation of a particular layer given some weights and biases and the activation of the previous layer in our network. What is more interesting is the fact that we can also calculate the gradients for the weights as well as the gradient for the previous layer activation given the gradient of the current layer. Let’s look at the figure below:
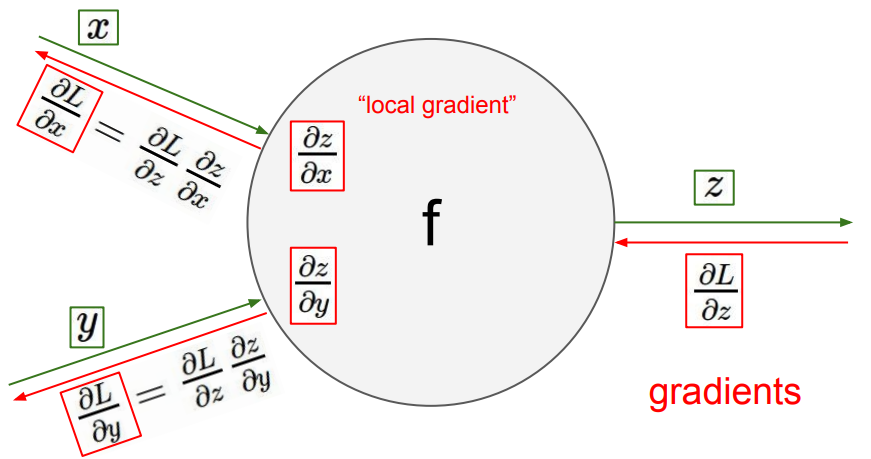
The above picture shows how easy it is to calculate the gradients for the inputs of the neuron given the gradient from the layer ahead. With that in mind, now let us look at a typical convolutional layer.
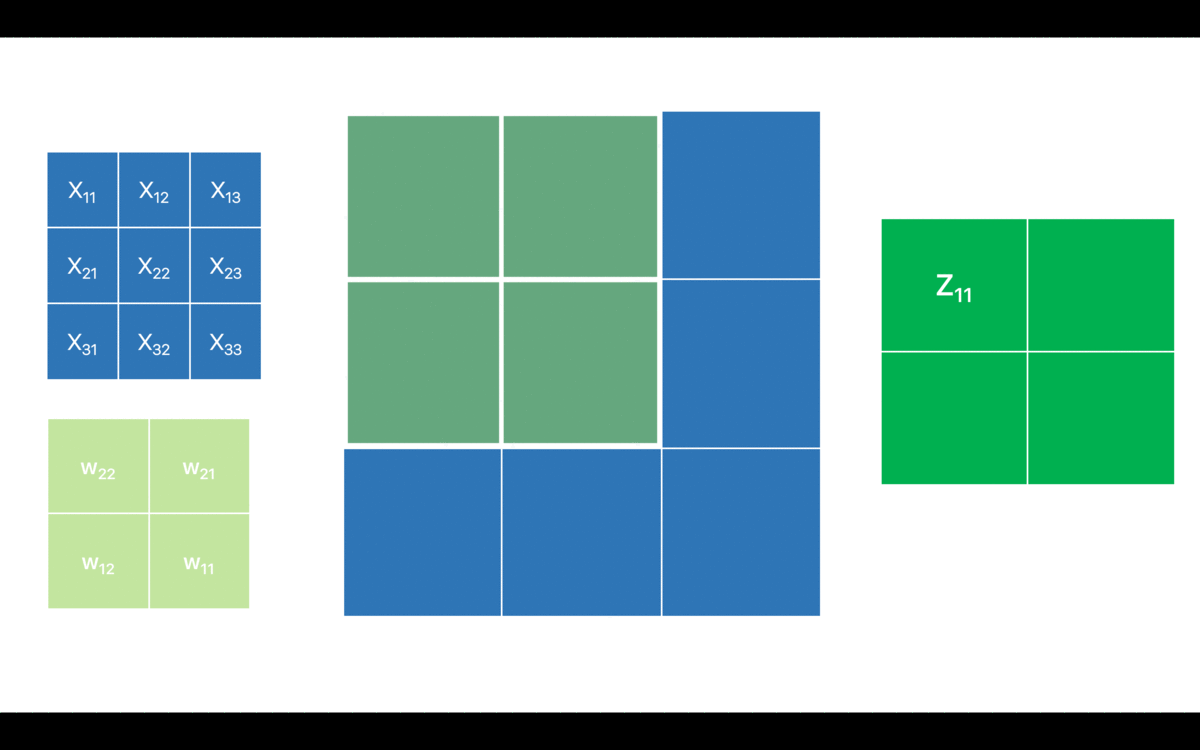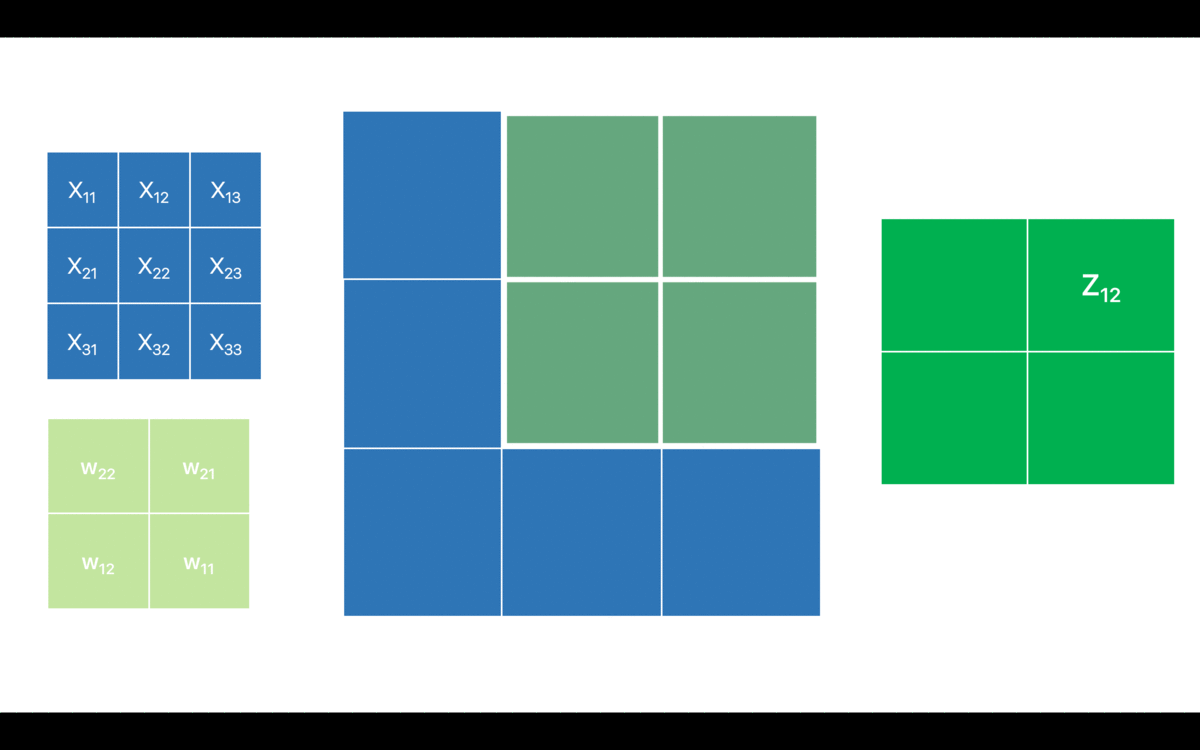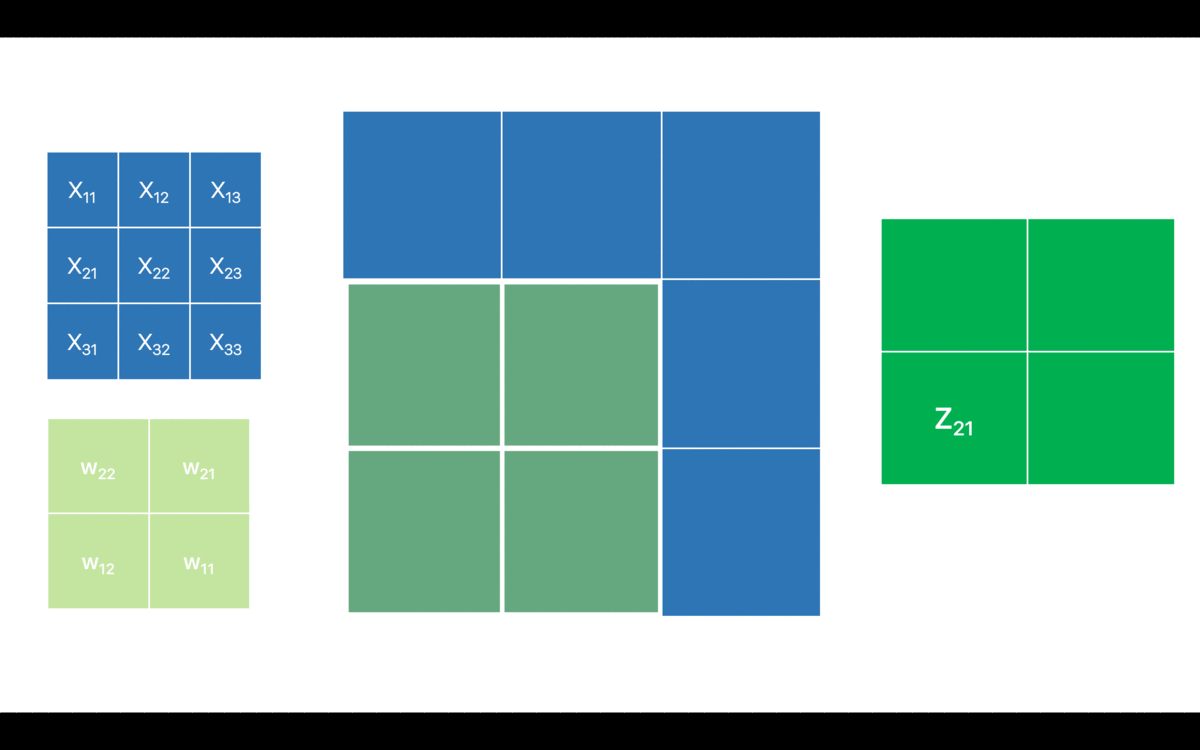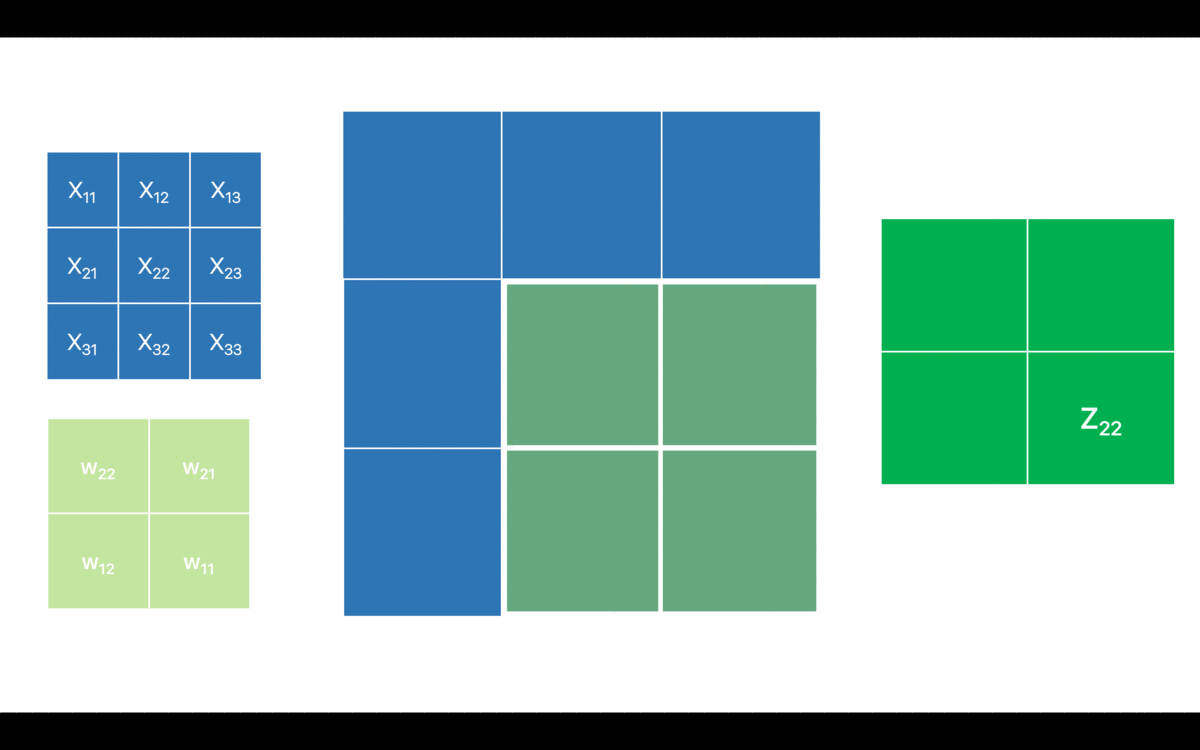
For simplicity, I have only considered one channel. I have denoted the pixel values for the input feature map as which is typically the notation for the input layer. However, that might as well be any intermediate layer for the network and in that case the will be the activations from the previous layer i.e. . is the output feature map before applying the non-linearity. I have also omitted the (bias term) in order to keep it as comprehensive as possible.
Now, let’s break down the above convolution operation in an attempt to relate it with the forward pass of a fully connected layer (matrix dot product operation).
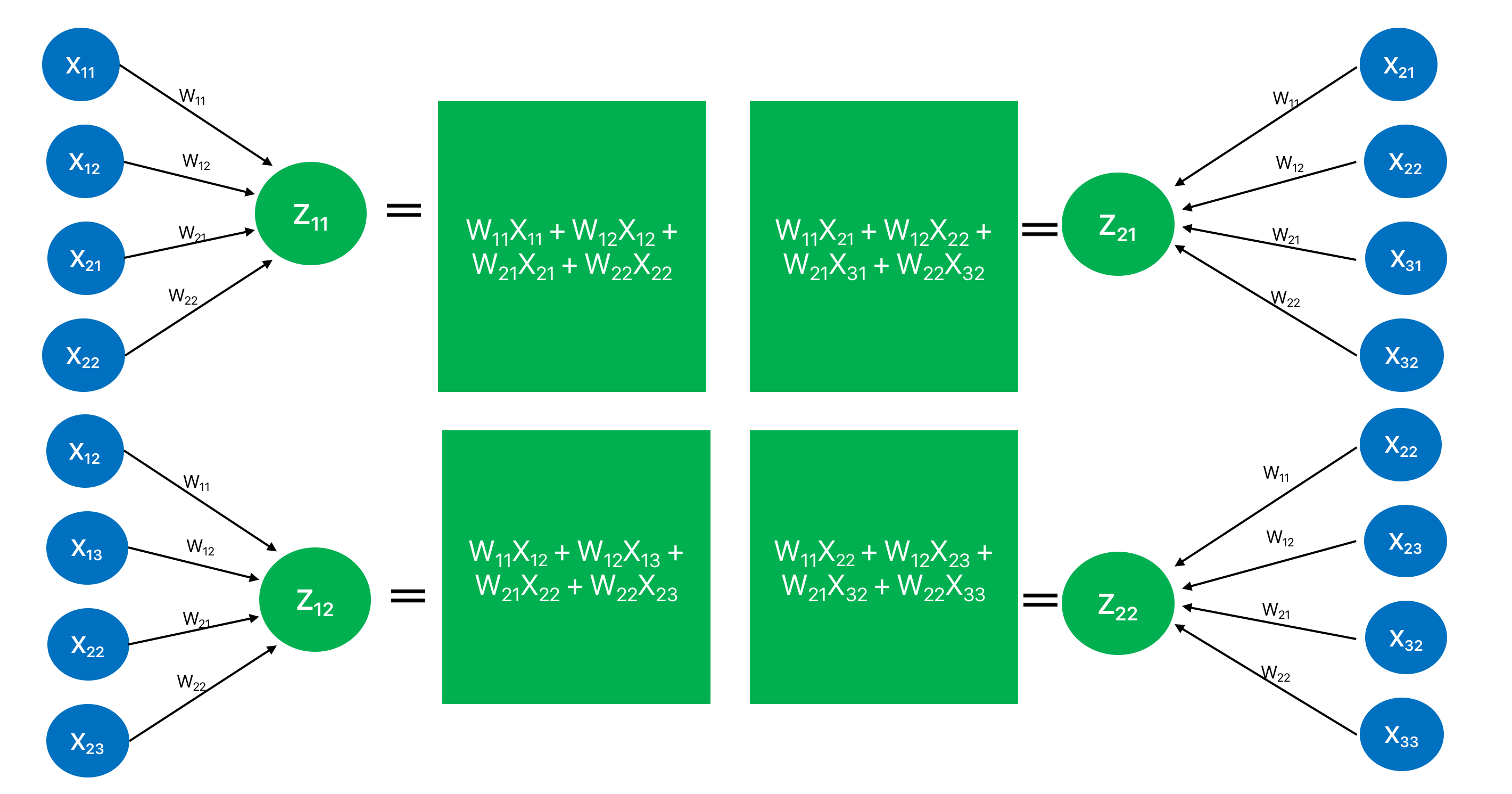
Looks quite similar to a fully-connected neural network, isn’t it? However, by the virtue of sparse connections the output feature map only corresponds to a few (and not all) neurons in the previous layer. Hence, the forward pass in the convnet is pretty straightforward. Before looking into the backward pass though, let’s recap the mantra for the backpropagation which is as follows:
Given , which is the gradient received at layer from the top of the network, if we can calculate:
- (and ), which is the weight (and bias) for the layer and
- , which is the gradient for the activation map for the previous layer i.e. layer all we are left to do is to iterate back from top to bottom updating the weights through gradient descent. In case you are wondering how the computation of helps our cause - then let me say this from you can easily obtain with a simple elementwise calculation as below:
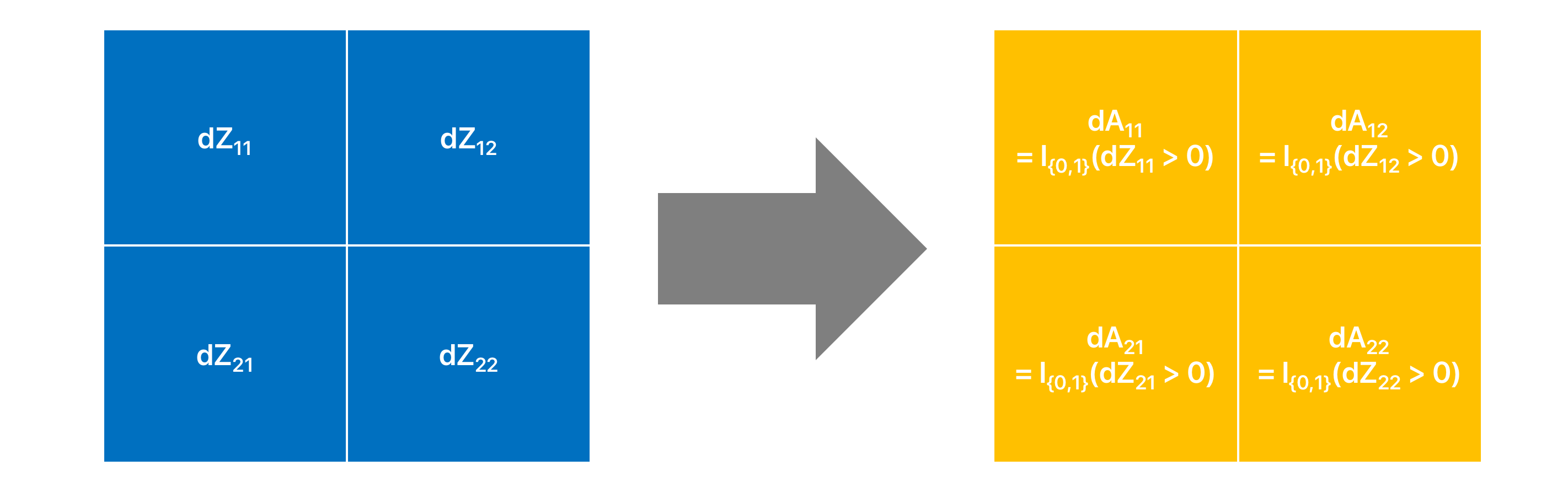
and with we can calculate and so on.
I just want to cover a couple of more things before looking into the backpropagation for a convolutional layer. This will help you follow more closely. First one is the chain rule of derivative, which I assume, you are already pretty familiar with. However, for the sake of continuity let’s just quickly brush up on that.
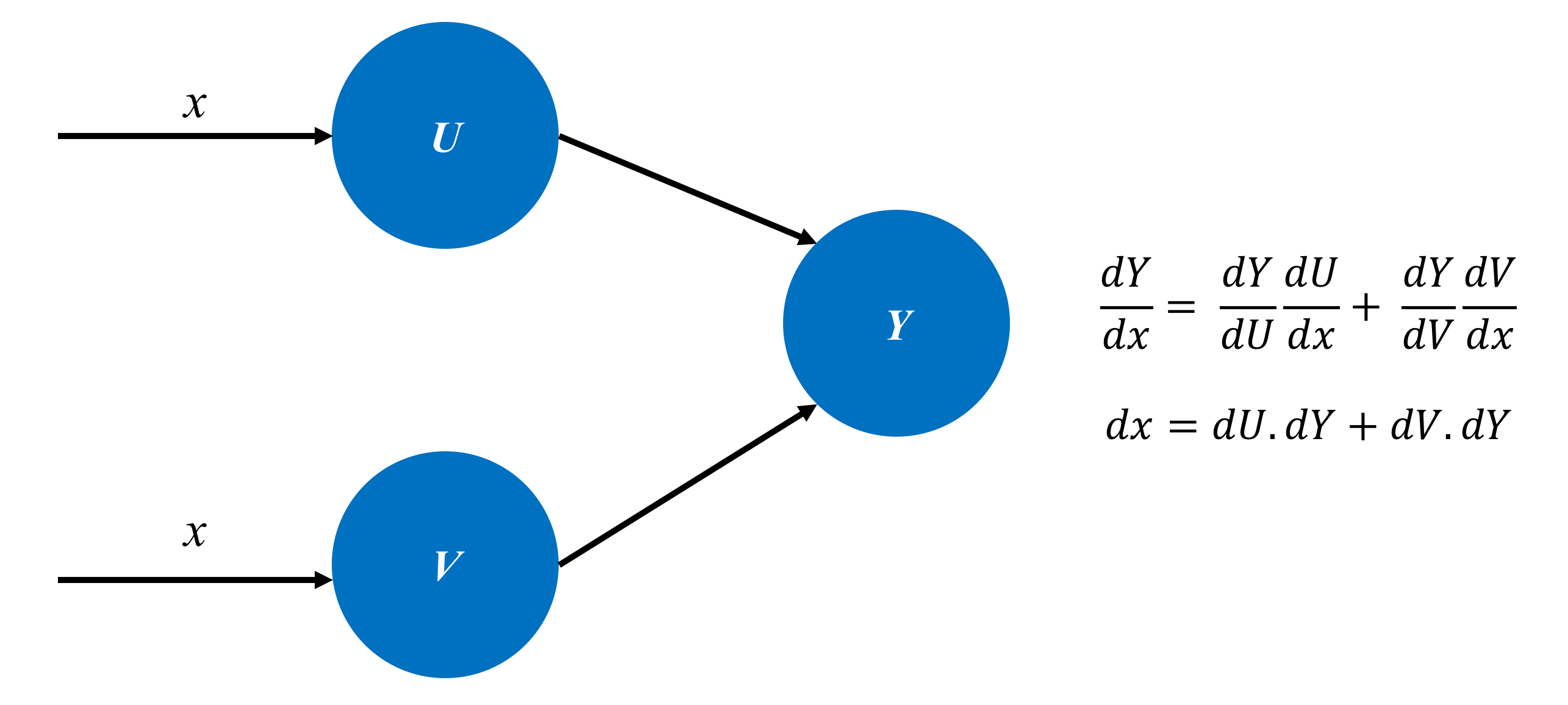
The takeaway from the above picture is that given the gradient of a function (say ), if we want to calculate - we have to take into consideration all the connections from to and take a sum of all the intermediate derivatives.
The last thing that I want to highlight is a full-convolution operation. Most of the time we are talking about convolution we are actually referring to valid convolutions, so let’s take a look how full convolution is different from a valid convolution.

Can you guess what would be the size of the output map?
… right, that’s a (3x3) output map which is bigger than the input map. Interesting, isn’t it?
Finally let us put everything together and try to accomplish our goal of computing the backward step for a convolution layer - more specifically calculating and given . To do that let’s first write out the equations for the forward pass:
So given we can calculate pretty easily (chain rule to the rescue):
Do you see what’s going on here yet? If not, take a look at the second set of equations more closely. Perhaps one at a time.
Think of the pixels in the input feature map that get affected by the weight term and you will quickly realise that that’s a (2x2) spatial map in the input feature map as below:
In the backward pass, we are taking that (2x2) map and convolving that with the which is also (2x2) and the result is our update . So the locality of connections remain invariant during the backward pass.
So obtaining from was quite straightforward. Now let’s find out how we can derive or in our case. We shall think of the connections that we talked about in the chain rule figure. For example, in order to calculate - let’s find out first how many connections are their from to . Turns out there is only one connection - that is through to . Hence, given , we can calculate as follows:
What about ? There are two connections - and . So, just like above we can obtain:
If we calculate the gradients for all the pixels in , we end up with the following matrix:
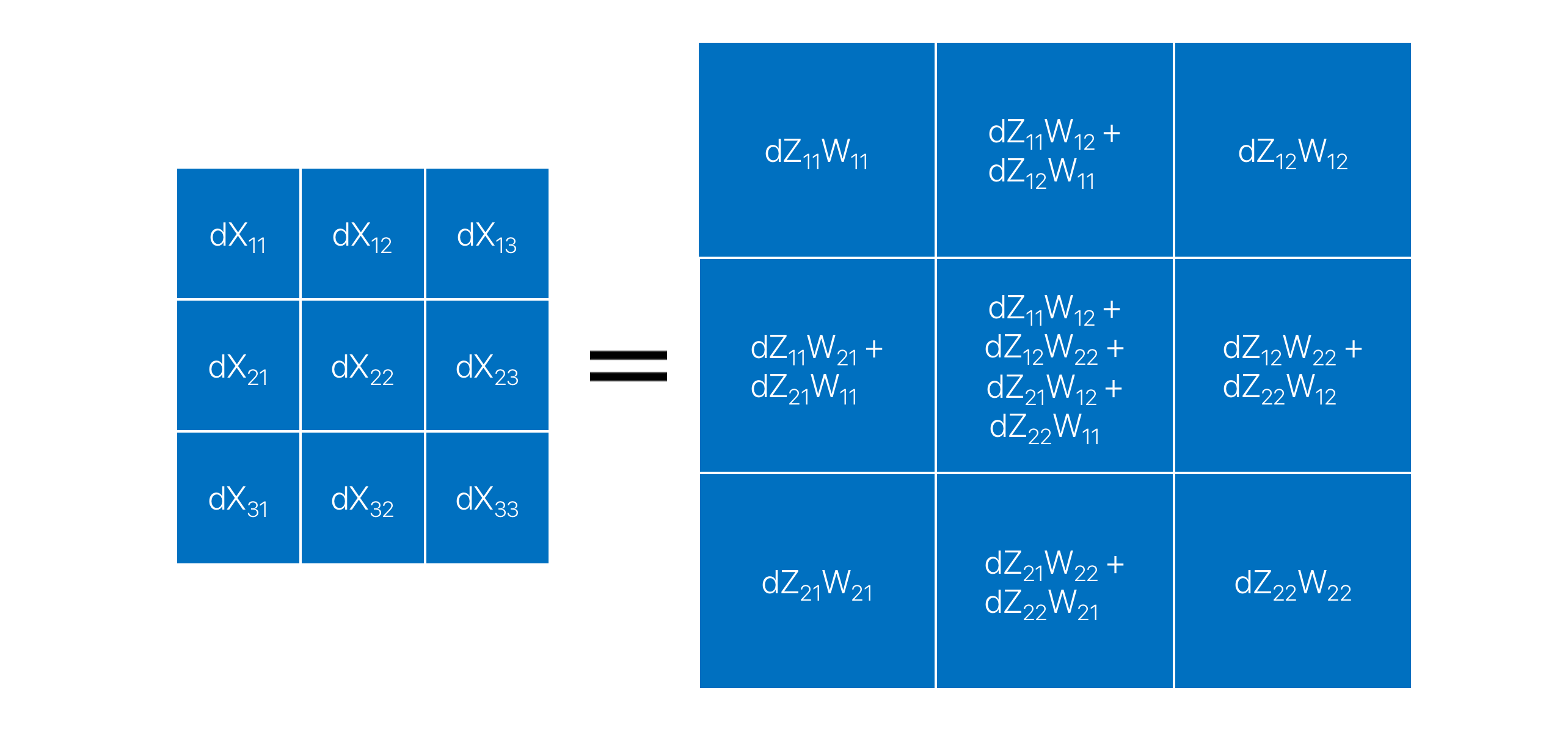
Nothing special so far. Plain simple math. But again take a look at the matrix carefully. Remeber the full convolution still? As it turns out if we rotate the kernel W (flip right twice) and perform a full convolution on , we get the exact same matrix as . That is:
More generically:
Which is quite similar to the backpropagation equation for a fully-connected layer - just the weight transpose for the latter is replaced by a convolution in this case.
That’s all for this article. If you have a feedback or question, please feel free to let me know in the comments.
Leave a Comment